Dans toute organisation d'une certaine taille, la notion de "silo" tend naturellement à émerger. En effet, la diversité des activités et la complexité inhérente qu'acquièrent les différents domaines favorisent l'apparition de barrières à l'entrée. Cette fragmentation est souvent le reflet d'une spécialisation croissante, nécessaire mais difficile à coordonner sans une vision commune. Les questions que l'on se pose deviennent de plus en plus complexes et nécessitent des expertises diverses afin d'être résolues. Aucun individu ne possède une vue holistique de tous les processus, ce qui pousse à scinder les tâches en plus petits morceaux qui deviennent ainsi plus faciles à gérer. En outre, l'analyse et l'interprétation des données nécessitent de développer une certaine expertise, souvent appuyées par l'usage d'outils qui deviennent hautement spécialisés.
Parmi ces silos, les silos de données (data silos) sont particulièrement problématiques. Traditionnellement, on qualifie de data silo tout ensemble de données isolées, accessibles uniquement à une unité ou un système, ce qui rend leur partage ou leur exploitation globale difficile. Vu que chaque département utilise ses propres formats, systèmes et espaces de stockage, il devient plus difficile de partager ou d'intégrer des données provenant d'autres équipes. Cette difficulté est exacerbée par l'absence de standards communs et de référentiels partagés. Cette scission est en partie naturelle : les habitudes de travail peuvent varier énormément entre les différentes métiers puisqu'elles ne sont pas composées des "mêmes personnes"; les profils souhaités varient énormément entre la comptabilité, la vente (sales), l'informatique, l'opérationnel ou la stratégie ...
Pourtant, tous ces métiers se heurtent aux mêmes difficultés:
S'il faut attendre deux semaines pour avoir une réponse et quatre autres avant de pouvoir ne serait-ce que d'accéder à la donnée, cela ne marchera pas. Ces silos ont de nombreuses conséquences (surtout humaines):
- Une gouvernance incohérente, chaque équipe souhaitant appliquer des règles différentes, mieux adaptées à leur métier ;
- Une communication fragmentée et une innovation au ralenti car il faut expliquer sans cesse à chaque nouveau cas le fonctionnement interne ;
- De la duplication et de la redondance, les équipes ignorant les développements réalisés par une autre. *Cette remarque est à pondérer par le fait que les personnes ne voient pas forcément les données de la même manière; les concepts sont flous, vagues et riches en nuances, une définition peut différer au sein d'une même équipe ;
- Collaboration limitée due à l'incompatibilité des outils et à la complexité des savoirs à acquérir que pour les maîtriser ... ;
- Une perte de confiance dans la donnée, qui devient difficile à tracer, à qualifier ou à réutiliser efficacement ;
À partir du moment où une méthode commune est adoptée, il devient plus simple d'implémenter un ensemble de pratiques partagées et cohérentes. Cela suppose de définir un socle minimal de gouvernance, suffisamment souple pour respecter les spécificités métier, mais assez robuste pour garantir l'interopérabilité.
Pour surmonter ces obstacles, de nombreuses organisations se tournent vers une approche plus intégrée : le data lake. Dans cet article, nous tenterons de répondre à ces problématiques par la mise en place d'une architecture de data lakehouse moderne en vaillant à clarifier les différents concepts qui lui sont connexes.
Quatre piliers pour dépasser les silos de données
Pour mieux comprendre les enjeux liés aux data silos, on peut les aborder à travers quatre grandes étapes fondamentales :
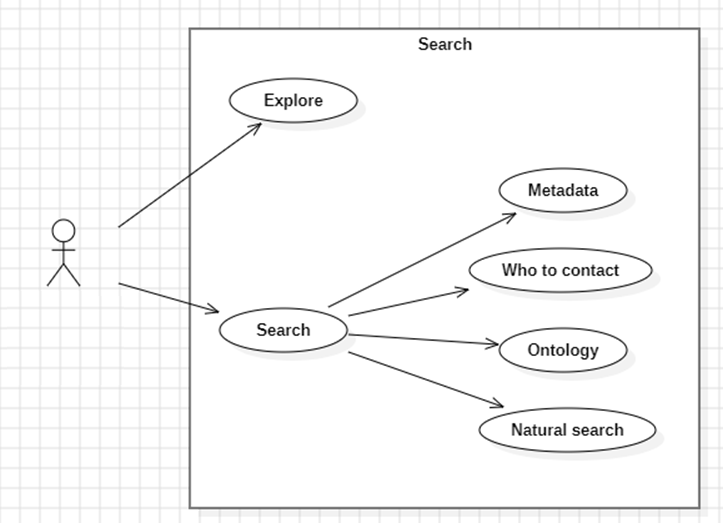
Rechercher
La première question que l'on peut se poser est:
Il y a deux grandes approches à cette question:
- Parfois, on erre sans objectif très précis, en naviguant parmi les données disponibles pour identifier un concept pertinent ou une piste intéressante, on explore (explore).
- D'autre fois, on a une idée bien plus précise sur ce que l'on souhaite, et l'on cherche à savoir si la donnée existe déjà, on recherche (search). Mais il y a plusieurs manières d'effectuer cette recherche :
- Au travers de métadonnées (metadata), qui permettent de classifier les données selon des domaines, thématiques, périodes ou lieux couverts, ...
- Qui contacter (Who to contact) ? On sait que c'est telle équipe qui s'en occupe ou on se souvient que Mme. TrucMuche a travaillé dessus, il y a 4 ans.
- Par le biais des concepts qui sont manipulés, de leurs relations ou de leurs raffinements, une approche ontologique (ontology). Parmi les entreprises belges, peut-être que je peux identifier les écoles ? La différence entre les établissements et leurs implantations est-elle bien prise en compte ?
- Ou plus simplement, par le biais d'une recherche naturelle (natural search), qui peut être tant exacte, que floue ou sémantique. On tape des mots-clefs, on a des résultats.
Accéder
Une fois que nous avons trouvé la donnée que nous cherchions, on souhaite y accéder (access) au travers des nombreux outils disponibles au sein de l'entreprise. Il faut bien veiller à ce que les applications métier employées par les utilisateurs permettent un accès fluide et intuitif aux données. Mais, il est doit être toujours possible d'offrir la possibilité à des profils plus expérimentés - tels que des data scientists ou développeurs (developers) - de retrouver l'information au travers de moyens additionnels.
La principale difficulté qu'une personne peut rencontrer est comment combiner l'information provenant de différents jeux de données afin d'obtenir ce qu'elle désire. Cette problématique est d'autant plus importante que certains jeux de données peuvent être particulièrement larges, et ainsi, poser des problèmes au sein de certains outils tels qu'Excel. Les données géospatiales ont généralement leurs propres logiques et sont liées à des outils fort différents des métiers plus classiques.
Integrer
Parfois, on souhaite jouer un rôle plus actif et ne plus être un simple consommateur de données, mais ainsi devenir également un producteur. Comment faire pour intégrer (integrate) sa propre donnée ?
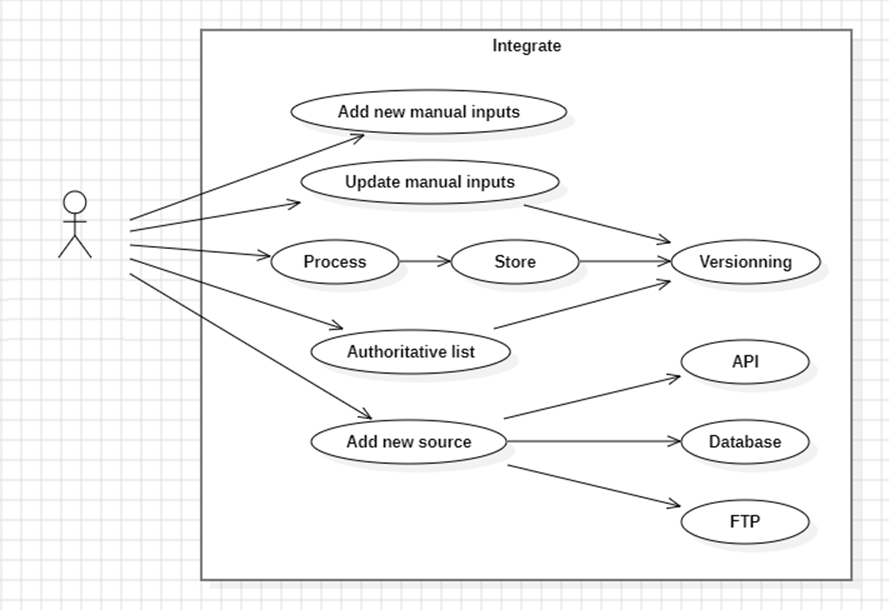
Il y a plusieurs formes que l'intégration peut revêtir :
- Les fichiers manuels (manual inputs) sont généralement des Excel fournis par le métier qui contient des informations pour paramétrer un traitement ;
- Les sources de données (data sources), qu'elles soient des API, des bases de données (database), des FTP, ... ;
- Les listes d'authorités (authoritative list) qui sont beaucoup plus transversaux (pensez à la liste des pays, des monnaies, des divisions au sein de l'entreprise, ...) et nécessitent souvent un processus bien défini de mise-à-jour (qui a les droits d'éditions, prise en charge de différentes versions, ...) ;
- Le cas général est que l'on traite (process) de la donnée et qu'on a ensuite besoin de stocker (store) pour ensuite la rendre disponible à d'autres utilisateurs ;
L'intégration ne doit pas être vue comme une opération ponctuelle, mais comme un processus continu, documenté et gouverné.
Documenter
Pour assurer le bon fonctionnement du système, il est crucial de maintenir une documentaire claire et à jour. Documenter (document) devrait être rendu le plus simple possible.
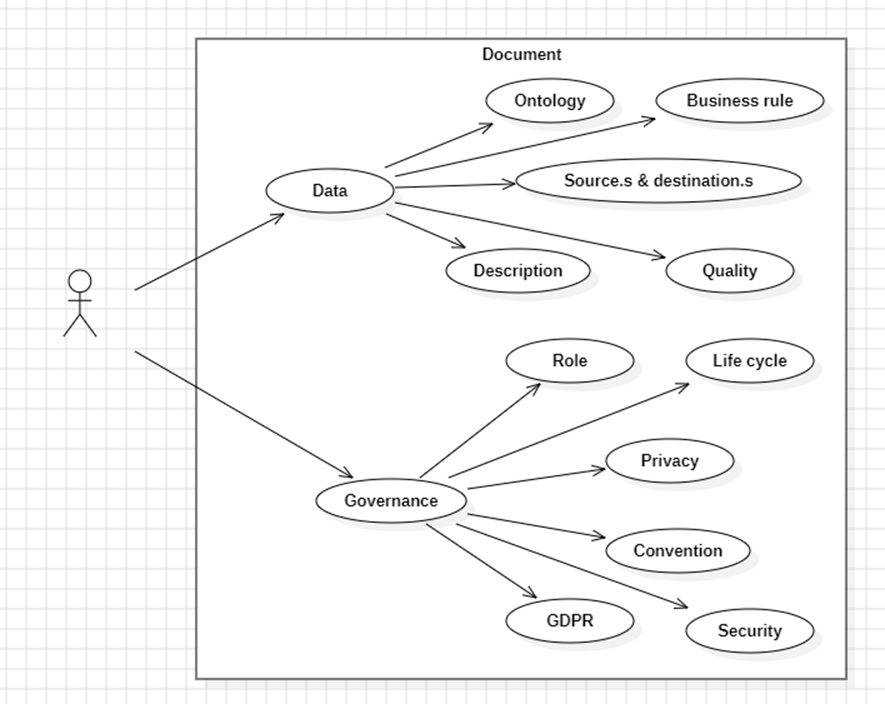
Il y a deux grands aspects à la documentation:
- La donnée (data) en tant que telle, ce qui est stocké:
- Lier des données à des concepts grâce au principe d'ontologie (ontology). Cette approche permet de dépasser les limites des mots-clés en structurant les connaissances autour de concepts partagés ;
- Expliquer pourquoi ces données sont construites avec leurs règles métiers (business rule) ;
- Fournir l'affiliation (lineage), d'où provient la donnée et où elle va, les sources & destinations ;
- Une description de la nature des données ;
- Une manière d'avoir un aperçu sur la qualité (quality) inhérente de la donnée ;
- La gouvernance (governance), quelles sont les règles:
- Rôle (role) des différents utilisateurs, ce qu'ils peuvent faire ou non ;
- Gestion du cycle de vie (life cycle), quand la donnée est créée, archivée et supprimée ;
- Une éventuelle convention sur la manière dont la donnée doit être manipulée ;
- Les niveaux de confidentialité (privacy) associées aux données ;
- La réglementation RGPD (GDPR) pour des données personnelles ;
- La sécurité (security) afin de gérer les deux cas précédents ;
Data as a "self" service
Une approche de données en libre service (data as a self service) peut s'avérer particulièrement efficace pour répondre aux multiples défis rencontrés par les organisations. Les grands points de divergences apparaissent souvent sur deux axes : la manière dont les données sont ajoutées au système, et la question de la responsabilité — qui décide, qui publie. Et quelles données doivent être rendues accessibles (opérationnelles, en transit, archivées, etc.) ?
Une approche fortement décentralisée peut être pertinente dans les contextes où:
- L'IT constitue un goulot d'étranglement (bottleneck) ;
- Une part importante des activités est externalisée ;
- Les différents métiers sont déjà fort autonomes et matures dans leur gestion.
L'objectif néanmoins est clair:
Ce type de projet soulève bien sûr de nombreux challenges, mais, ici, nous ne nous concentrerons principalement que sur les aspects techniques et non sur les facteurs humains et organisationnels.
Concrètement, il s'agit de concevoir une solution évolutive (scalable) et flexible qui permettrait à de nombreuses équipes décentralisées de pouvoir collaborer efficacement. On souhaite permettre à chaque équipe de pouvoir continuer d'opérer selon leurs propres méthodes, tout en respectant un ensemble minimum (socle minimal) de pratiques qui permettent de garantir cette interopérabilité sans être trop restrictif sur les métiers.
Mordern lakehouse
Pour instaurer une véritable interopérabilité entre les systèmes, il est essentiel d'imposer une protocole de communication commun. Ce protocole doit être compréhensible par tous et facilement intégrable aux solutions existantes, et suffisamment souple que pour s'adapter aux évolutions futures.
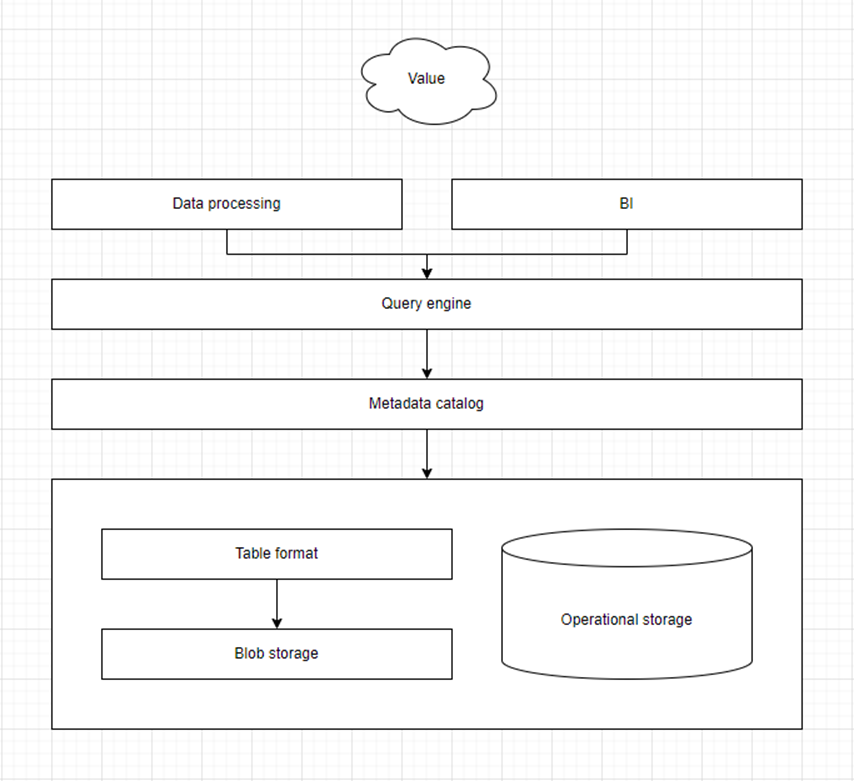
En fonction de la complexité des opérations que l'on souhaite effectuer sur les données, plusieurs couches fonctionnelles peuvent être identifiées:
- Blob storage: la couche la plus élémentaire consiste à stocker des "fichiers" - dans un sens très large du terme - dans un système de blob storage. Il s'agit d'un espace de stockage extensible, comparable à une sorte de système de fichiers mais qui possèdent des capacités étendues ;
- Table format: sur cette couche, on peut construire une vue que l'on peut désigner par table format qui permet de structurer la donnée en tant que telle. Cela concerne tant les formats des fichiers qui sont stockés que la gestion des différentes versions d'un même fichier à travers le temps. Cette dernière fonctionnalité rappelle l'usage de "git" (source control) qui permet d'étendre la gestion des versions (versioning) au delà d'un simple fichier, mais à un ensemble de fichiers ;
- (Metadata) catalog: cette touche technique centralise des métadonnées, dans un sens technique du terme. Elle répond à deux fonctions principales:
- Lié la sécurité à la donnée en elle-même. Assurer la sécurité des accès et garantir la cohérence des opérations. Comme un même fichier peut avoir plusieurs versions, on souhaite avoir des permissions plus précises, ou basées sur des concepts (liées à un jeu de données).
- Permettre de faire correspondre un identifiant (namespace) à une vue spécifique d'une donnée (en cas de multiples versions) et ainsi s'assurer que les opérations demandées font sens, qu'il ne soit pas possible de demander une information qui n'existe pas (à cause d'une colonne mal nommée par exemple) ;
- Query engine / compute engine: cette dernière couche permet d'interroger et transformer les données de manière transparente, indépendamment de leur emplacement physique. Cela peut tant jouer un rôle d'intégration, de fédération, que de requête. Concrètement, elle permet de répondre à la problématique de faire la jointure entre deux tables situées dans deux bases de données différentes, combiner des jeux de données séparés.
Il est à noter que certaines couches sont optionnelles, il est parfaitement possible d'avoir un query engine directement sur un blob storage. En revanche, la couche table format et metadata catalog vont souvent étroitement liées.
Blob storage
Une solution de blob storage est une solution de stockage universelle, capable d'héberger tant des données structurées, que semi-structurées ou non-structurées. Certaines personnes font la différence entre object store, block storage ou file store, par la suite, nous n'effectuerons pas la différence, on veut juste stocker des "trucs".
À noter que lorsque l'on emploie le mot blob storage, on peut implicitement parler de 'blob storages'. Tant que la documentation est claire, cette pluralité devrait rester transparente pour les utilisateurs.
Les principales fonctionalités sont:
- Fournir un espace de stockage extensible, sans contrainte forte sur l'espace disque ;
- Être accessible, tant depuis le cloud que en local (on-premises) ;
- Indépendant d'une instance (machine) en particulier ;
- D'agir comme un système de fichiers distribué ;
Il est essentiel de retenir que le blob storage doit être avant tout vu comme un protocole de communication et non une solution figée, la technologie pourrait être remplacée sans que tout ce qui en dépende ne soit affecter.
Les deux protocoles les plus répandus sont S3 (Amazon) et ADLS (Azure).
Table format
La couche table format permet d'avoir une vue consistante sur les différentes données, tant sur le plan sémantique (où on aurait différentes versions de fichiers en simultané), que sur le plan technique et la manière dont sont stockées ces données concrètement, comment les informations sont structurées au sein même du fichier. Cette information est stockée en plus de la donnée, c'est une métadonnée mais technique.
Dans les métadonnées attachées au fichier en lui-même, on peut retrouver de l'information concernant les données et leur distribution (au sens statistique du terme). Cela peut être utile afin de cibler efficacement les données pertinentes et de ne consulter que les données relatives à notre demande (données pour une certaine année, par exemple).
Pour l'aspect purement local à la donnée, il est d'usage d'employer des "parquet" comme fichiers plats, ils ont l'avantage de proposer une distribution de leurs données et d'offrir un format intermédiaire entre le mode colonne (plutôt orienté pour l'analytique) et ligne (pour l'opérationnel).
Pour les problèmes de gestion de versions, il existe deux solutions: Delta Lake et Apache Iceberg. Toutes deux sont vraiment des solutions très intéressantes dans leurs fonctionnalités et qu'il est intéressant d'envisager.
(Metadata) catalog
Le problème que l'on rencontre généralement lorsque l'on stocke des fichiers plats est qu'il manque un système unifié de gestion des métadonnées, des différentes versions des tables et de leur accès. Les query engine peuvent s'appuyer sur ce type de catalogue centralisé afin d'employer leurs systèmes de métadonnées pour travailler plus efficacement.
Ils permettent aussi de jouer d'intermédiaires pour le contrôle des accès, de l'audit ou de la sécurité. En effet, il est difficile de s'assurer que les règles de sécurité (au niveau des colonnes ou des lignes) soient bien respecter parmi tous les outils qui tenteraient d'accéder aux données. Ils offrent également de meilleures garanties ACID dans un système distribué.
Il y a beaucoup de solutions à ce niveau parce que ce domaine est en plein essor, mais parmi des classiques, on retrouve: Nessie, Lakekeeper, Polaris, ...
Query engine
Cela représente davantage la couche de traitement de la donnée et de l'exploitation de toutes les données stockées. Cela permet surtout de fédérer les sources de données, d'aller puiser dans les différents systèmes afin de combiner l'information de manière transparent pour l'utilisateur.
Ce sont les outils tels que: Spark, Trino, ...
Data catalog
Le catalogue de la donnée (data catalog) constitue la pièce centrale du système. Il permet de faire le lien entre les besoins des métiers exprimés dans les sections précédents et les solutions technologiques sous-jacentes. C'est par son intermédiaire que la majorité des utilisateurs interagissent avec l'écosystème de données.
Documentation & intégration
Nous l'avons dit, la documentation se décompose en deux parts, une sur les aspects liés à la donnée en tant que telle, et une sur les aspects de gouvernance.
Comment peut-on proposer une manière aux utilisateurs de documenter (éventuellement) en profondeur les données qu'ils manipulent tout en permettant à des systèmes informatiques de stocker ou d'exploiter de nouvelles données ?
Il y a deux grands cas à considérer:
- Ajout manuel: les utilisateurs déposent leurs fichiers directement au sein du catalogue afin de les rendre accessibles pour leurs différents outils. Ce moment peut être mis à profit afin de collecter un maximum d'informations possibles ;
- Ajout automatisé: les utilisateurs rajoutent de la donnée à travers leurs outils spécialisés de traitement de données. Dans ce cas-là:
- Soit ils doivent préparer et documenter leur espace de stockage en amont (et on retombe dans le premier cas) ;
- Soit la solution technique documente elle-même le document qu'elle souhaite sauvegarder ;
La documentation automatique par la solution présente quelques challenges. En effet, les informations ont des chances d'être beaucoup plus sommaires que ce qu'un utilisateur pourrait fournir dans l'interface graphique du catalogue de donnée. Il est donc recommandé de permettre aux utilisateurs de revoir et enrichir les nouvelles données générées afin d'améliorer la qualité globale du catalogue.
On pourrait se demander si on ne pourrait pas avoir un système de file d'attente (queue) qui écoute les modifications sur le blob storage, mais on risque:
- d'avoir beaucoup de bruits parasites ;
- de devoir tout documenter au lieu de se concentrer sur les choses utiles, toutes les données stockées ne sont pas nécessairement utiles ou exploitables ;
DCAT-AP
Une manière de documenter toutes ces données est de passer par DCAT-AP (Data Catalogue Vocabulary - Application Profile). C'est une spécification européenne qui permet de décrire les jeux de données de manière standardisée et interopérable. Concrètement, DCAT-AP est une extension du vocabulaire DCAT (Data Catalogue Vocabulary), développé par le W3C, qui sert à structurer les métadonnées des catalogues de données. L'objectif principal de DCAT-AP est de :
- Faciliter la recherche de données ;
- Assurer l'interopérabilité sémantique (ontologiques) entre les catalogues ;
- Encourager la réutilisation des données ;
Concrètement, DCAT-AP définit une structure commune pour décrire les jeux de données, les distributions (fichiers téléchargeables), les licences, les producteurs, etc. Tout en garantissant l'utilisation de vocabulaires contrôlés (tels que EuroVoc, Dublin Core, INSPIRE, ...) pour garantir la cohérence des métadonnées. DCAT-AP propose beaucoup de concepts liés à la gouvernance, mais peut être enrichis avec des champs additionnels pour documenter des concepts plus spécifiques au contexte de l'entreprise.
En tout cas, les utilisateurs doivent fournir les informations minimums requises par DCAT-AP au catalogue afin qu'elles deviennent disponibles par son biais et ainsi exposer les autres fonctionnalités.
Ontologies
DCAT-AP est avant tout une ontologie. C'est-à-dire, un modèle de données contenant des concepts et relations permettant de modéliser un ensemble de connaissances dans un domaine donné. Plutôt que de définir précisément ce qu'est un “chat”, on peut s'accorder sur le fait qu'il s'agit d'un félin, qui est un animal, qui interagit avec les humains, qui se nourrit, ...
Ce concept d'ontologie est extrêmement vaste et dépasse largement la simple documentation technique. Il répond à un problème beaucoup plus intéressant que la bête documentation des champs d'une table. Une adresse d'une unité d'habitation aura toujours la même définition, peu importe où cette information est stockée. Une manière de standardiser les définitions.
Malheureusement, DCAT-AP ne propose pas de manière de documenter les schémas de données (les colonnes des tables, types et contraintes), il peut être nécessaire d'étendre la notion afin de permettre à l'utilisateur de rentrer dans des détails s'il le souhaite.
Mise en œuvre
En pratique, l'utilisateur doit fournir au minimum :
- Le catalogue (catalog) ;
- Le jeu de données (dataset) ;
- Le fichier ou la ressource associée, la distribution ;
- Le lieu de stockage des données ;
- L'origine des données (si possible) ;
Ces différents niveaux (catalog, dataset, et dans une moindre mesure distribution) doivent être créés à un moment où un autre et sont ensuite référencés par un identifiant technique. Tout le reste n'est que "pur bonus", mais plus le travail est complet, meilleures seront les fonctionalités de recherche.
Les métadonnées fonctionnent en éventail, c'est-à-dire qu'il existe plusieurs niveaux de complétion de la donnée, mais on peut s'arrêter à un niveau plus sommaire.
Accéder
Le catalogue de la donnée ne permet pas d'accéder à la donnée directement. Par contre, il fournit:
- La possibilité d'obtenir le lien (URI) vers la ressource (S3, API, ...), qui peut être ensuite employé programmatiquement.
- Un identifiant (namespace) exploitable par le query engine.
- Une possibilité d'exporter des données vers Excel pour des utilisateurs moins familiers à l'informatique en passant par le query engine.
Ontologie
La gestion des ontologies suit un processus distinct. L'architecture d'entreprise définit une bonne partie des termes employés au sein de l'entreprise. Cette information est exportée de leur logiciel de modélisation afin d'être complétée et enrichie par les différents métiers (à la wikipédia).
Les ontologies permettent de créer un langage commun entre les métiers et les systèmes, réduisant les ambiguïtés et facilitant les échanges.
Cette ontologie "locale" à l'entreprise est complétée par d'autres ontologies déjà existantes afin d'être le plus complet possible.
Recherche
La recherche se base sur toutes les informations stockées au sein du catalogue. Elle se veut tant exacte, que floue (fuzzy) ou sémantique afin de permettre à l'utilisateur de trouver quand même ce qu'il cherche (entreprise vs compagnie).
Pour les schémas, un processus automatique intervient pour indexer les colonnes et le contenu (si le format le permet) afin de proposer une documentation préliminaire à corriger et à améliorer par le métier.
Conclusions
Sur le papier, les choses semblent pourtant simples. Mais, dans la réalisé, c'est une toute autre paire de manches. Il faut développer un ensemble conséquent de composants afin d'obtenir une solution à la fois présentable pour les métiers et suffisamment robuste pour inspirer la confiance. Et comme souvent, le diable se cache très fort dans les détails.
Tout d'abord, le premier défi réside dans le choix des différentes technologies, qui doivent impérativement pouvoir s'intégrer les unes aux autres. Si, sur le principe, elles sont interchangeables, en pratique, chaque solution comporte des subtilités qu'il faut anticiper et bien veiller à vérifier. Par exemple, la librairie Python liée à Apache Iceberg (pyiceberg) est encore loin d'être aussi mature que son équivalent en Java. Ce manque de maturité devient problématique lorsque l'on souhaite bénéficier de fonctionnalités avancées comme la gestion des données géospatiales avec Iceberg 3.0 ou la présence de bugs pouvant introduire de la data corruption.
Mais au-delà des considérations techniques, les véritables obstacles sont souvent humains. Se mettre d'accord sur les concepts, les processus, les rôles et la vision commune demande du temps, de la pédagogie et une forte coordination interdisciplinaire.
La réussite d'un projet de lakehouse repose énormément sur la capacité à fédérer les acteurs autour d'une vision partagée. Bien que le lakehouse apporte une réponse structurée aux (data) silos, il ne peut à lui seul résoudre les enjeux humains, organisationnels ou politiques. Il doit s'inscrire dans une stratégie plus large, incluant la formation, la gouvernance, et l'alignement des visions métier/technique.
En facilitant l'accès, la documentation et la réutilisation des données, le lakehouse encourage une culture orientée données. Les métiers deviennent acteurs de la donnée et il devient possible de collaborer sans devoir réinventer la roue à chaque projet.
Il vaut mieux rester pragmatique. Il est préférable de choisir une approche incrémentale pour le data catalog : commence par les datasets les plus critiques ou les plus utilisés, puis élargir progressivement (mieux vaut une documentation à jour qu'un modèle exhaustif outre-daté). Vouloir tout centraliser d'un coup peut générer des résistances et des erreurs de gouvernance (ex. confusion sur les rôles de Data Steward ou la nécessité de les segmenter par périmètre métier).
Il ne faut pas hésiter à organiser des ateliers courts et ciblés avec les métiers pour valider les modèles de données, les besoins de reporting ou les cycles de vie des données. Cela permet de lever rapidement les ambiguïtés et de créer de l'adhésion. Clarifier aussi tôt que possible la terminologie et les traductions des concepts, surtout si plusieurs langues ou métiers sont impliqués. Un simple tableau de correspondance (ex. "purchase order" vs "bon de commande" vs "bestelbon") peut éviter des heures de débats inutiles.