Introduction
La programmation sur GPU a gagné en importance ces dernières années, surtout depuis l’apparition des librairies de deep learning modernes telles que Tensorflow, Pytorch, Keras, Caffe, MXNet, … En effet, les GPU proposent un tout autre modèle de calcul qui permet d’atteindre des performances plus que subtentiels (facilement un facteur 10) sur des processus de traitement de données 'simples’ (multiplications de matrices et consorts). De plus, les GPUs continuent d’obtenir des gains massifs de performances à chaque génération alors qu’on commence à ressentir une certaine stagnation au niveau des CPUs.
Néanmoins, la programmation sur GPU existe déjà depuis de nombreuses années (début des années 2000), avec l’apparition du pipeline programmable des rendus graphiques (et la notion de shader). L’usage des GPUs à d’autres finalités que 'graphiques’ (gpgpu) a malgré tout été évoqué à peine plus tard (avec le fameux tri en 2005 1). Seulement, cela était resté assez confidentiel à cause d’un modèle de programmation fort différent, du manque de support technique à cette fin (CUDA et OpenCL) et des limitations techniques qui ne rendaient pas cela si intéressant (c’était il y a 20 ans). Mais avec le temps, les outils de développements se sont créés et les améliorations techniques les ont rendu particulièrement intéressantes dans le traitement de certaines tâches. Seulement, les problématiques sur GPU sont souvent fort différentes parce que là où on lancerait peut-être une dizaine de threads sur CPU, sur GPU, il est d’usage d’en lancer plusieurs dizaines de milliers. En vous montrant le mode de fonctionnement des GPUs, on espère que vous comprendrez mieux à quelles tâches sont adaptées ces composantes.
Exécution
ℹ️ Les architectures évoluent avec le temps, les nombres sont données de manière indivicative mais sont suffisamment représentatifs que pour former une image mentale.
ℹ️ Dans cet article, nous privilégions l’usage de la terminologie de CUDA mais nous mentionnerons à chaque fois le terme équivalent chez OpenCL.
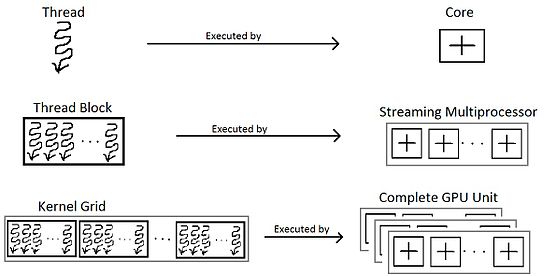
Thread
La plus petite unité de calcul présente sur un GPU s’appelle un 'thread' (ou work-item), on parle parfois de processor (ou processing element). Cela correspond à la même notion que l’on retrouve classiquement sur un CPU, un flux de calcul indépendant*. La plus grande différence avec les CPUs est l’espace disponible afin de stocker des variables, le stack. En effet, vu que de très nombreux threads peuvent être lancés, la mémoire associée à l’ensemble des stacks peut très vite devenir conséquente.
Généralement, on est limité à 32 registres de 32 bits, mais on peut en avoir plus qui sont alors stockés dans la mémoire globale, mémoire nettement plus lente, mais dont la gestion se fait en toute transparence. Cette limite de registres s’applique tant pour les registres de données, que pour celle des instructions; cela devient surtout problématique pour les appels à fonction; il faut éviter à tout prix les récursions, au risque de perdre à chaque fois les registres liés aux paramètres (et la call-stack).
Les performances peuvent très vite se dégrader lorsque l’on franchit ce seuil de 32 registres. Mais cette limite est variable, et n’est active que lorsqu’il est possible d’arriver à 100% d'occupations des threads. Dans l’idée, si vous n’arrivez qu’à employer 25% des threads, vous aurez donc accès à 4x plus de registres (mais vous serez, de fait, 4x plus lent). Il faut davantage comprendre qu’il y a une mémoire de taille fixe qui est partagée entre tous les processeurs de manière équitable.
Les fameux Ray Tracing (RT) cores et Tensor cores peuvent être vus comme des instructions spécialisées à ces usages, un peu comme on retrouvait les 'floating-point accelerators’ (FPA) à une époque (au travers du WMMA pour le tensor mais les fonctionnalités de Ray Tracing ne sont pas publiquement disponibles). À noter qu’il existe des instructions de type SIMD sur GPU (mais qui opère uniquement sur 32 bits).
Warp
En réalité, le warp (ou wavefront) est la plus petite unité de calcul 'physique’. Il s’agit d’un ensemble de 32 threads. C’est de là que vient l’expression SIMT pour *Single Instruction Multiple Thread* pour désigner le modèle de calcul des GPUs.
Chaque instruction décodée est exécutée sur tous les threads appartenant au même groupe sur un CUDA core (ou SIMD unit). C’est particulièrement efficace puisqu’on peut facilement appliquer 32 fois la même opération pour une seule unité de temps. On parle parfois, sans doute à tort, de SIMD (Single Instruction Multiple Data), mais les deux concepts ne sont pas si éloignés et les CPUs peuvent exécuter du code prévu initialement pour GPU grâce aux instructions SIMD.
Seulement, ce fonctionnement rentre en contradiction avec la notion de flux indépendant des threads. Dès que le code se retrouve à devoir effectuer des codes différents (branchements conditionnels), il y a une divergence. Pour cela, à chaque warp est associé un mask qui représente le fait que le thread soit actif ou non (et donc que le résultat est jeté à la poubelle ou non; on retrouve ce même concept dans les instructions AVX).
Les branches sont exécutées jusqu’à retomber sur une partie commune où la divergence se terminera. La conséquence étant que la vitesse sera d’autant plus divisée que le nombre d’embranchements est grand, même si on a une division en 1 et 31, c’est équivalent à une division en 16 et 16. Dans les processeurs plus modernes, cette pénalité de divergence peut être parfois réduite parce qu’il n’est pas rare que des instructions soient partagées entre toutes ces branches (notion de tile).
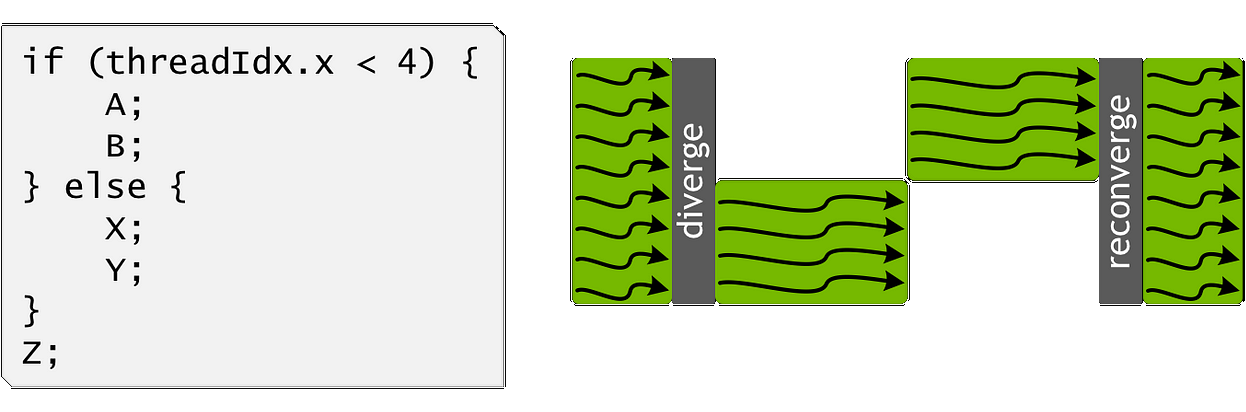
Thread block
Les warps sont regroupés en thread block (ou work-group). Ces thread blocks de, classiquement, 32 warps sont associés à un Streaming Multiprocessor (SM) (ou Compute Unit) qui se charge d’ordonnancer les warps et d’exécuter physiquement les instructions (comme un CPU). Les conséquences sont multiples:
- Un thread block est exécuté jusqu’à terme, il est donc possible d’attendre une barrière, un endroit dans le code où tous les warps d’un même thread block sont;
- On ne peut pas atteindre une même barrière entre plusieurs thread blocks1;
- C’est donc ce SM et le nombre de warps qui conditionnent la quantité de mémoire allouée à chaque thread;
Grid
Les thread blocks sont eux-mêmes groupés par grid (ou computation domain). L’idée étant qu’on ne sait a priori pas le nombre de SM qui existent, on lance donc autant de thread blocks que nécessaire afin de compléter la tâche et c’est l’ordonnanceur qui se chargera de leur attribuer un SM en temps voulu.
Le code qui est exécuté de bout en bout sur la carte graphique est appelé kernel et ces paramètres de lancement conditionnent les dimensions de la grid. Pour synchroniser les thread blocks, il faut donc attendre l’exécution complète du kernel et en lancer un nouveau1.
Finalement, il existe la notion de multi-grid qui représente l’exécution sur plusieurs cartes graphiques.
- Depuis l’arrivée des cooperative groups, on peut attendre une synchronisation d’une grid ainsi que d’une multigrid. Néanmoins, il y a quelques conditions à respecter.↩
Mémoire
La mémoire est divisée en plusieurs sections, qui ont des performances et caractéristiques intrinsèques.
Global memory
La global memory représente tout l’espace mémoire disponible pour le GPU. Cela ne se limite plus forcément à la mémoire physique puisqu’il existe maintenant des facilités afin de proposer une vue unifiée de la mémoire, qu’elle vienne de la mémoire centrale (RAM) ou directement d’un disque dur ! Évidemment, les performances seront conditionnées par l’emplacement physique dans lequel repose cette mémoire; mais avec les dizaines de giga disponibles actuellement, cela permet de répondre à de nombreux besoins. La bande passante mémoire des GPUs est également largement plus élevée, un facteur 10 par rapport à un CPU n’est pas à exclure (mais c’est vraiment comparé des pommes et des poires).
On peut éventuellement préallouer un espace de mémoire de travail afin d’être sûr de ne rester qu’au sein du GPU, mais il sera difficile de le modifier (même s’il est possible d’allouer directement de la mémoire au sein du GPU).
La difficulté vient évidemment de la concurrence. Il existe des instructions primitives d’atomiques mais pour des structures de données plus complexes, vous êtes livrés à vous-même. On peut éventuellement déclarer des parties comme étant read-only (mais le gain n’est pas extraordinaire).
Shared memory
La shared memory (ou local memory) est l’espace mémoire disponible au sein d’une SM et donc 'partagée' par toutes les warps d’un même thread block. Elle est particulièrement utile parce qu’elle permet de diminuer la contention lors des écritures et elle est généralement plus rapide que la mémoire globale (de mémoire le facteur est seulement 3x).
Local memory
La local memory (ou private memory) est celle associée à une warp et à ses threads. Elle est particulièrement rapide (j’ai le souvenir d’un facteur 100), mais elle ne permet que de manipuler les registres et de communiquer entre les threads au sein d’une même warp.
Elle s’emploie au sein de primitives qui permettent, par exemple:
- De tester si une valeur est égale à une constante et de récupérer tous les threads satisfaisant cette condition;
- De réduire les valeurs au sein d’une même warp (par exemple faire la somme) et renvoyer le résultat à tous les membres de la warp;
- D’élire un représentant unique qui fera une opération de manière isolée (pour la concurrence);
Il est d’usage de d’abord effectuer une réduction au sein d’un warp, ensuite d’un thread block (dans la mémoire partagée) et enfin agréger toutes les valeurs au sein de la mémoire globale.
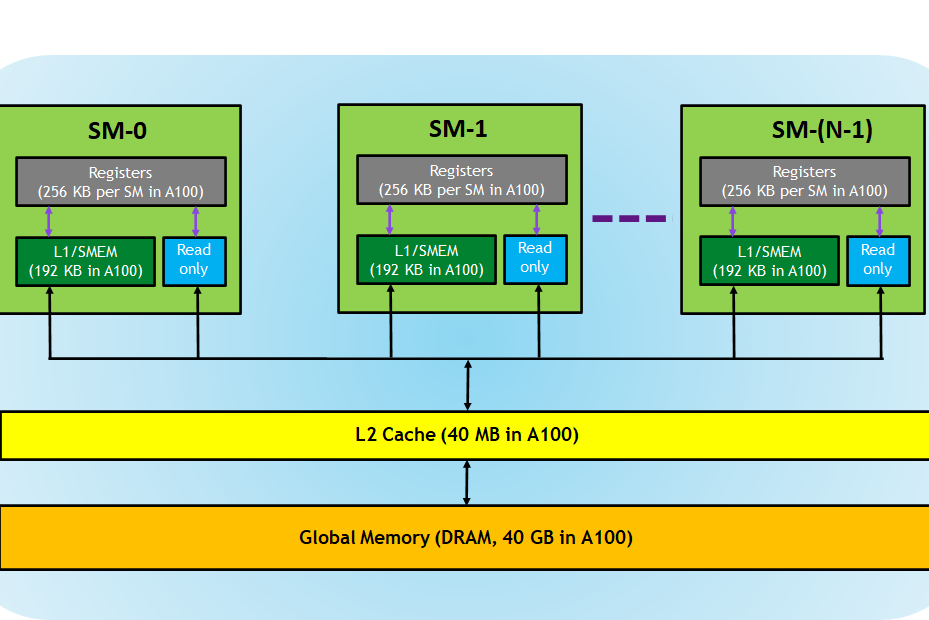
Cache line
Un des éléments transversaux à cette mémoire est la notion de cache lines. Toute la mémoire est divisée en cache lines (typiquement de 128 bytes), même si vous ne demandez qu’un bit en mémoire, 128 bytes seront rapatriés. Les conséquences sont multiples:
- Plus vous demandez des informations à des endroits aléatoires en mémoire, plus les performances seront lentes; il faudra charger jusqu’à 32 * 128 bytes en mémoire avant de pouvoir exécuter une warp; (Ne vous attendez pas à une baisse de performances d’un facteur 32, la bande passante des GPUs est monstrueuse en comparaison d’un CPU).
- Plus vous alignez vos accès, meilleures seront les performances, si votre warp accède pile-poil à 32 floats consécutifs, cela pourra se charger en une seule cache line;
- Il y a une notion de prefetching;
- Il existe le problème de bank conflict, où la mémoire partagée est divisée en banks et les accès y sont sérialisés (à moins d’un broadcast, où la même valeur est démandée par tous ceux accédant à cette bank);
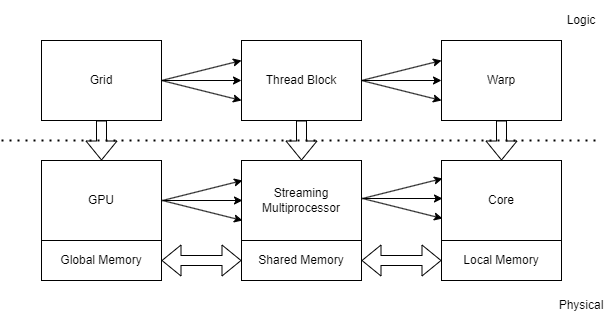
Récapitulatif
En résumé, nous nous retrouvons avec ce schéma-ci:
Programmation
Après avoir vu ces aspects plus techniques, on peut s’intéresser aux problématiques qui peuvent intervenir au niveau logiciel.
Parallélisme
Le premier point qui vient en tête est l’aspect hautement parallèle des cartes graphiques. Il faut donc veiller à employer des algorithmes qui peuvent être facilement paralléliser. Faire attention qu’il n’y ait pas de dépendances entre des sous-tâches qui peuvent être parallèles, même si on peut lancer des kernels au sein d’un même kernel, attendre le résultat des enfants avant de continuer est particulièrement inefficace sur GPU.
C’est un arbitrage subtil entre les surcoûts (overhead) et les problèmes de synchronisation; il vaut mieux avoir une bonne compréhension algorithmique et comprendre les différences entre complexité algorithmique et gains pratiques. Il existe des modèles de calcul théorique dédiés au GPU (Parallel external memory model) où l’on cherche également à diminuer le nombre d’accès effectués à la mémoire.
Load balancing, faire en sorte de répartir au mieux la charge afin de maximiser l’usage de toutes les unités de calcul. Si une seule warp est lente, tout sera ralenti.
Hardware
Il y a une très grande variété de modèles de GPUs, où les différences d’architecture font que des petits changements d’algorithmes ou de configurations peuvent avoir des fortes conséquences en termes de performance. Arriver à exploiter au maximum un GPU est vraiment loin d’être trivial, mais le jeu en vaut vraiment la chandelle, arriver à un facteur 100 par rapport à un CPU est possible (10 est considéré comme très bien).
La mémoire est un enjeu crucial: malgré cette vue unifiée qui est proposée, les ressources sont limitées et on passe une bonne partie de son temps à investiguer cette problématique afin de maximiser le débit et diminuer la latence.
La communication interne au sein du GPU ou entre le CPU ou le GPU ou encore entre les GPU peuvent fortement nuire aux performances. Profiter des capacités asynchrones de communication est un véritable challenge. D’autant plus si cela s’intègre dans une ferme de GPUs (GPU clusters), avec la mise en place de stratégie de distribution du travail.
Software
Débogage et profilage: vous imaginez bien que débugger un processus où 10’000 threads sont exécutés en parallèle ne fonctionne pas totalement de la même manière … Parfois il vaut mieux travailler au papier et au crayon.
Au moment où je m’étais intéressé à ce domaine, les librairies étaient particulièrement rares et beaucoup de choses, même primaires, étaient à implémenter soi-même. Il y a beaucoup de considérations à prendre en compte et je comprends que certaines solutions soient plus discutables à mettre en place (typiquement les structures de données).
Le développement sur GPU nécessite le développement de connaissances plutôt spécialisées. Prouver que son code fonctionne en parallèle est d’un tout autre acabit. C’est un domaine qui évolue encore assez vite et il faut essayer de rester au fait des nouvelles technologies, solutions et optimisations. Par exemple, écrire un spinlock ne fonctionne pas parce que la condition de progrès n’est présente dans les deux branches.
Autres
Les GPUs sont beaucoup plus primaires par nature parce que de nombreuses fonctionnalités présentes sur CPU n’existent simplement par sur GPU (parce qu’elles ne présentent pas d’intérêt). La mémoire étant partagée, il est éventuellement possible d’accéder à de la mémoire qui ne nous appartient pas. Mieux vaut rajouter une couche de protection mémoire, cela éviterait de faire fuiter des données confidentielles qui ne nous appartient pas. D’autant qu’il n’y a pas de systèmes de chiffrement/déchiffrement.
Conclusions
Les GPUs représentent une source vraiment très puissante de calculs qui a su révolutionner le domaine du high-performance computing. Malgré son avantage indéniable en termes de performances brutes, il y a beaucoup de challenges et considérations à prendre en compte avant de partir sur cette voie. J’espère qu’après cette présentation du modèle de calculs sur GPUs, vous comprenez mieux à quels types de tâches elles sont mieux adaptées.
J’espère vraiment que la situation a évolué en termes de librairies disponibles au sein même du GPU, c’était vraiment un des plus gros freins auxquels je m’étais confronté. Aucune librairie "standard" (offrant des algorithmes un peu classiques "map", "filter", "reduce", …) n’existait au sein même du GPU et, la situation semble encore et toujours persister. Je comprends qu’il existe des choix techniques d’implémentations qui rendent le concept difficile, mais les APIs devraient être claires avec la notion de 'cooperative_group’. La réelle difficulté me semble surtout émerger dans la définition de structures de données (et éventuellement des algorithmes les exploitant).